MQ主备方案
公司自研的MQ基本功能稳定后,开始提高可用性,首当其冲的就是要做主备。我们的MQ基本上还是借鉴了阿里的rocketMQ的方案,所以在HA这块也差不多。
主备同步方案
主备的数据同步主要由HAService负责:
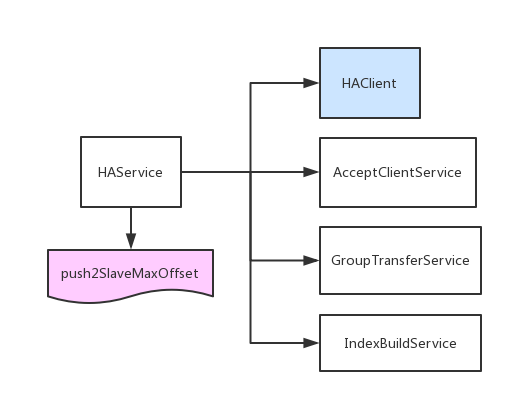
- HAClient:负责连接master,并负责跟master的心跳,以及数据读入
- AcceptClientService:负责监听slave的请求,每来一个连接,创建一个HAConnection
- GroupTransferService:负责等待主从同步完成,有些消息必须要主从同步完才返回(第一期优先级低)
- IndexBuildService:负责在slave节点上将消息重放生成seq文件
主备数据同步流程
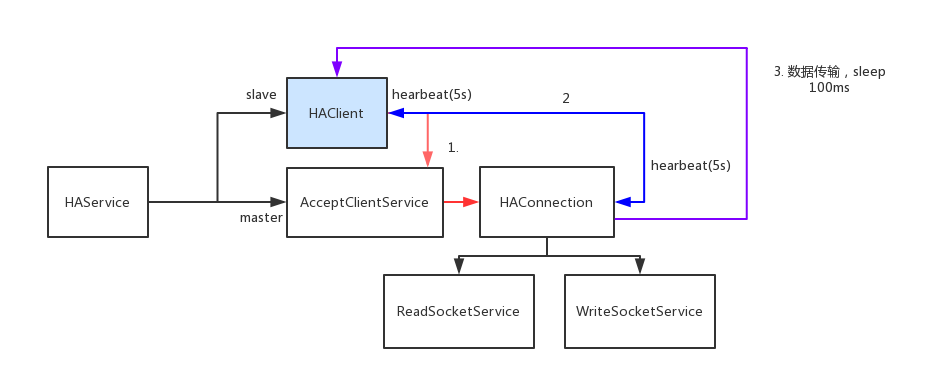
主备之间的数据交互主要有下面几个流程:
- 建立连接。slave节点知道自己是备份节点后(通过监听ZK),主动向master发起请求,master收到后,初始化HAConnection负责与slave节点的交互
- 互发心跳。一方面,slave定期向master发送心跳,并汇报自己的最大偏移,master以此确认slave存活并且是正常状态(依据slave汇报的偏移量);另一方面,master也要定期向slave发送心跳,告知slave节点下次需要拉取的位置,slave以此判断master存活并且是正常状态(依据master下发的拉取位置是否跟自己保持一致).互相发送心跳保证了对双方的灵活性。
- 数据同步。master会定期监测自己消息文件的位置,如果消息文件的最大位置和slave汇报的位置不一致了,说明有新的消息,就会把消息推送到slave上。
可以理解为,同步流程就是:心跳+增量
备份节点数据回放
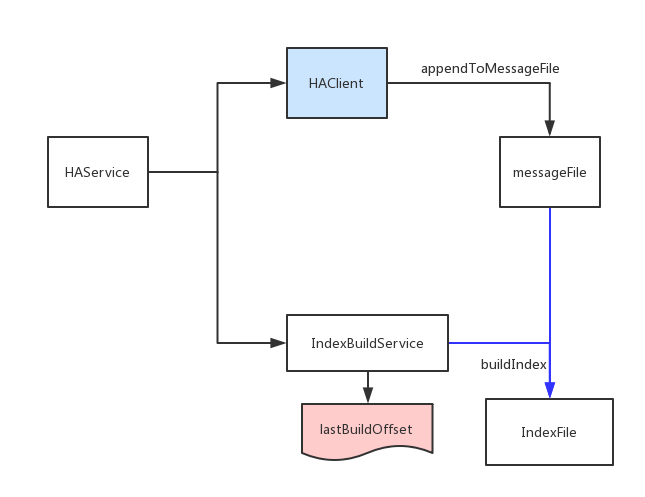
在备份节点回放的流程跟正常接收消息的流程是一样的,都是依赖于IndexBuildService来构建seq文件。不过这个地方有一个关键点,就是,如何保证seq(位点)在master和slave上保持一致?
下面是我们的消息体的设计:
- topicId (2 bytes)
- partitionId (2 bytes)
- seq (8 bytes)
- bornIp (4 bytes)
- bornTime (8 bytes)
- storeTime (8 bytes)
- bodyLength (4 bytes)
- propertiesLength (2 bytes)
可以看见,消息体里面有:topicId,partitionID,seq. topicId和partitionId可以定位Index文件的目录(我们的index存储结构跟rocketMQ的consumeQueue一样),根据seq可以定位到具体的indexFile:
offset = seq * SEQ_UNIT_SIZE(每个index的大小)
(seq file create position) = (offset - (offset % SEQ_FILE_SIZE(每个indexFile的大小)))
记得当初看MQ的代码的时候,对消息体里面存放seq还有疑问。因为index文件存储了消息的offset,相当于index—>message, 如果在message里面存放了seq就相当于:message—->index,当时觉得message没有必要指向index,毕竟写代码的时候双向引用给人的感觉不是很舒服。
而等到做主备的时候,才发现消息体里面存放seq的好处了。这样的设计就相当于,每个消息是一个自身完备的,当消息换了一个环境的时候,它能够依照自己的信息把消息完整的还原出来,包括消息体,seq。这在后面做设计的时候,在考虑主备的时候,要好好注意一下。
同步确认
有的消息比较重要,需要消息同步到备份节点才OK,那么,就需要一个确认的过程。
一些简单的方案:
- 每次master接收到一个消息,就把消息推给slave:同步流程
- 每次master接收到一个消息,把seq(或者offset)放到一个list里面,异步将list里面的seq同步到slave,然后回调:异步流程
很明显,异步流程要好一些,但是,上面的异步流程却不是一个很好的方案:
- 需要维护额外的队列
- 异步同步流程跟主备数据同步流程怎么协调?
参考rocketMQ的实现:
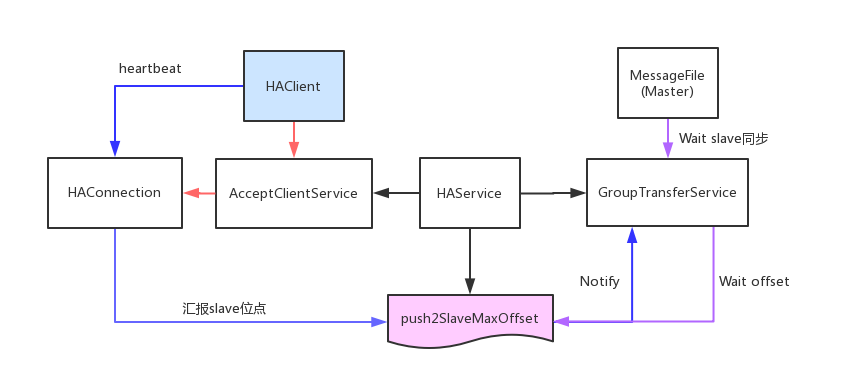
该方案把上面的第2个方案简化了,每次收到一个message后,通过groupTransferService来等待一个offset,而每次主备同步后,都会更新push2SlaveMaxOffset,然后唤醒那些等待offset小于push2SlaveMaxOffset的请求。这样做的好处是:既实现了异步,又简化了同步模型
其他的数据,例如消费位点,topic,分区等,我们都是通过ZK来共享,这样就不需要想rocketMQ那样单独起一个同步服务了。
主备切换方案
主备切换是通过手动切换的,因为zk不稳定啊,网络问题啊,都会出现一些抖动,所以自动切换还是有很多坑的。
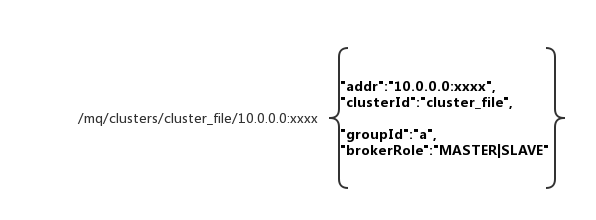
这个是我们broker在zk上记录的节点数据,里面有分组ID,相同分组ID的机器互为主备,通过brokerRole来区分。切换的时候,会修改ZK,然后,客户端会监听到zk配置变更,就把消息的发送和拉取切换到备份节点上。
另外,切换的时候还要注意打开broker的写开关,因为备份节点默认是不允许写的,我们现在也不允许读,后面还有继续优化,允许读请求,尤其是那些拉取时间偏早的请求,打到备份节点,这样可以防止master节点过多的页换进换出,增加IO负担。