再谈稳定性工作(二)
最近系统又出了几次故障,虽然每次复盘都会做一些改进,但是,如果系统的完善一直靠故障来驱动,这个代价就有点大了。所以尝试系统化的梳理一下,看看还有哪些方面我们没有涉及到的,及时补齐。
整体思考
一个系统,可以在总体上以下面的视角来看:
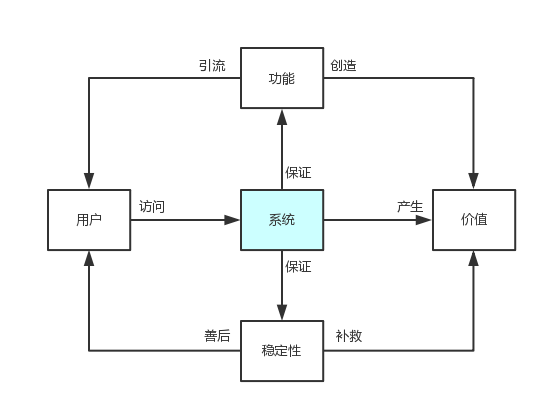
系统对外承接用户,对内创造价值;为此,系统作出两个保证:
- 提供功能性保证:这个是系统的本质,只有提供一系列功能,才能引流,才能创造价值
- 提供稳定性保证:系统尽最大努力保证,在任何情况下,都对外提供符合预期的功能,当然,只能尽最大努力,至于结果如何,就是我们说的SLA了。
总体上,我们分为两个部分讨论:一个是如何保证稳定性,一个是当稳定性被打破时,我们要做出哪些响应,以及为什么。
稳定性保证
要梳理清楚一个系统如何做出稳定性保证,先从一个系统的边界和组成开始:
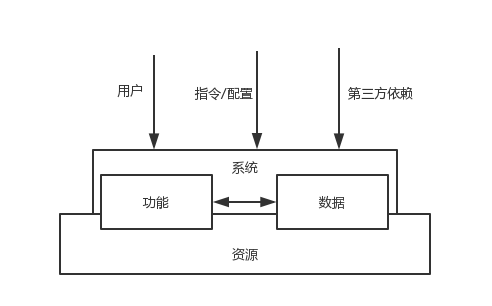
常见的系统基本包括:
用户/流量:系统总要承接流量,或者是直面外部的用户,或者其他系统的流量,我们统一抽象为用户。这一块基本面临两个问题:
- 容量问题
- 风险问题
指令/配置:现在的开发模式,例如,配置化,模版化,引擎化等等,都造成一个现象就是一个系统的输入不只是用户流量,而且包括很多系统自身的指令,配置等,这些操作会让系统从一个状态转移到另外一个状态。这部分输入可能存在的问题是:
- 很容易成为盲点:一个开发随意打开了一个线上开工谁都不知道,结果导致系统的状态发生变化,或者系统隐藏bug被触发。
- 造成的影响可能会更加严重:因为这些指令或者配置往往会很大程度让系统发生根本性改变,一旦出错,系统的损失会更加巨大
第三方依赖:这是常见的问题,现在基本都是微服务架构,所以,这块的一些常见工作大家基本都知道,比如,超时控制,降级等
功能/性能:这块基本取决于系统的逻辑+数据,虽然我们期待在经过测试之后,功能以及性能没有问题,但是大家都知道这基本不可能
数据:系统的核心,现实资产的抽象,一般我们都是通过冗余来保证数据的稳定性。
资源:底层支撑层,例如,CPU,内存等
上面在每一个点都有可能出现问题,我们需要经常思考如何应对:
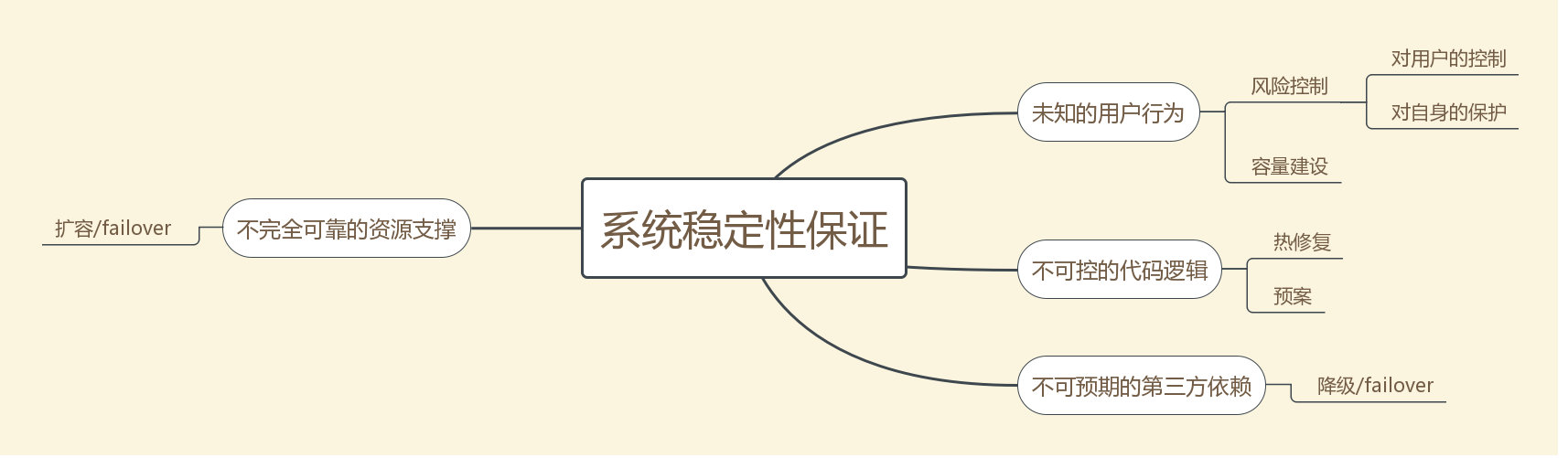
故障还是发生了
我们尽量做出稳定性承诺,但大家都知道,故障还是可能发生,一旦故障发生,我们要启动下面的流程:
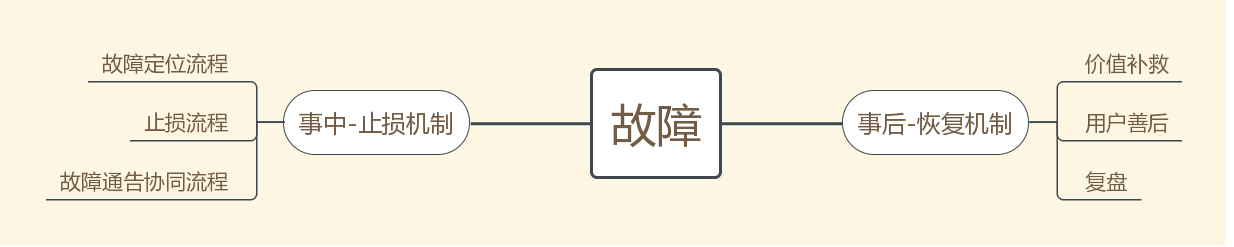
里面的每一步都需要逐步完善和细化,但目标是明确的:
- 事中:快速止损。为了实现快速止损,需要快速定位,为了快速定位,需要运维的报警体系,需要各个业务平台的协同定位等等一系列流程
- 事后:尽量恢复和补救。两个层面:对内,挽回资产,对外,补偿用户。这两个一定要思考清楚,一个故障不只是恢复了那么简单,要考虑清楚对公司资产,对用户的种种影响。
流程建设
只有当即使做了好多工作,还是发生故障之后,才会知道流程的重要性。

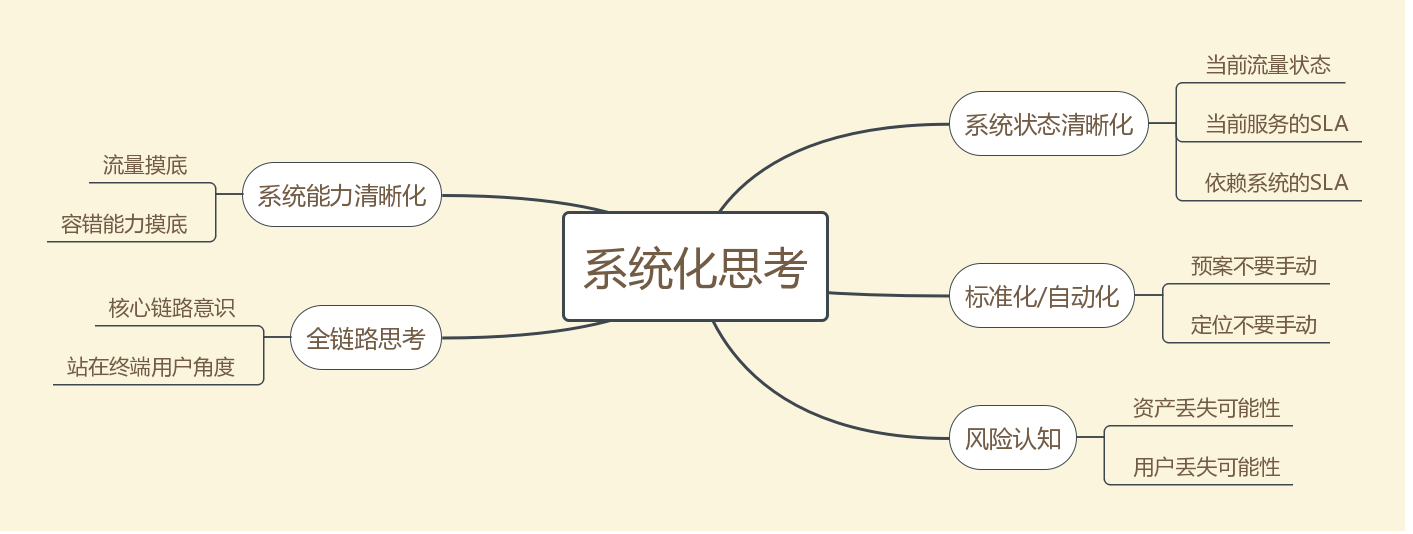
系统化思考
思考系统稳定性的时候,具体到每个系统都要差异,但是,有一些系统性的思考方式我觉得可以通用的: